For my third round of creating primary prediction models for the presidential nomination, I focused just on the Democratic nomination between Clinton and Sanders. Here, I publish four new models, two of which correctly fit all 32 of the Democratic votes, and two that have only missed one vote.
I have not recalculated Republican-side models. Previously, I generated two models that had, as of March 23, correctly fit all states that had voted to that point. Aside from that, it looks like no matter what happens with the primary results, the GOP convention will become an open/brokered process. In that case, regression models about the primaries would be pointless, so I did not invest the time to recalculate them.
My last Democratic models, created just prior to the March 26 caucuses where Sanders swept Hawaii, Washington an Alaska in landslides, used 3 & 4 variables to correctly predict fit almost all of the states which had voted prior to those caucuses, and in all cases except one, correctly predicted these three wins for Sanders (one of the three models predicted a large Clinton win in Hawaii). The first of those three models, M1D, use unemployment (Dec 2015), no religious affiliation, out of state migration, and an average of the 2008-2012 presidential election votes, and so far has only 1 error, Iowa, out of the 32 states that have so far voted. The second model, MD2, so far has only 2 errors, Iowa & Oklahoma.

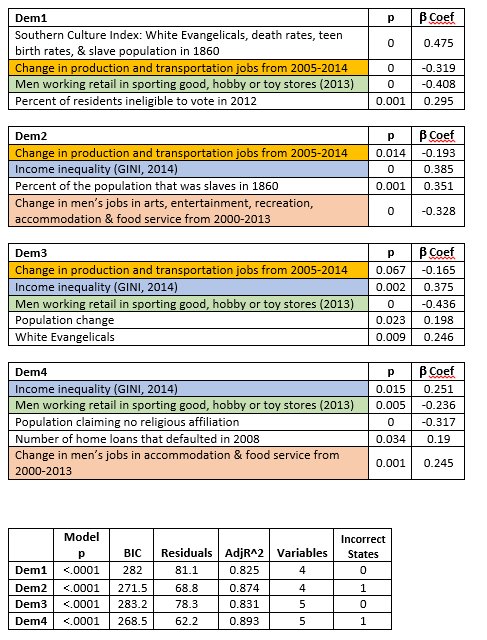
In these new models I do two things. First, I updated the algorithm to include the three states that have voted since I generated my last models. Second, I used the "numerically best" models, regardless of their application to theory. For the previous models I published, I ruled out those models that may have looked good on paper, but used obscure variables, like "number of men who worked in sports, hobby and toy stores in 2013," "women who work in the pharmaceutical retail stores," or "men who work in tobacco stores." While those are, to some degree, economic variables, and I was giving preference to economic variables, it is hard to make a broader theoretical cased based on these variables, since you would have to explain why these three specific job variables did a good job fitting the voting patterns, and the other 800 jobs variables had far less success. However, for these models, I throw theory to the wind, and include the obscure jobs variables. I filtered out those models that used more than two jobs variables.
There are some differences in predictions between these models, and the models from March 23. For example, in the previous models, Delaware was firmly in the Clinton camp, and both Rhode Island and West Virginia had two models putting them firmly in the Sanders camp. However, these new models put Delaware firmly for Sanders, and now the latter two are firmly showing for Clinton. There are several other states, like Maryland, New Jersey, New Mexico, South Dakota, and Wisconsin, where the previous models were contradictory, and solidly for either Sanders or Clinton now, or where they were previously showing a trend for one, but now are less clear. Given that the more recent models include more data, I would tend to support the findings of the newer models. However, MD1 from the first set of models still only has one incorrect state, and MD2 still only has two incorrect states.
One of the most common variables that appeared in the best models, is the income inequality variable, GINI, for 2014. As this value increases (approaches 1), it signifies more inequality, and as it decreases (approaches 0), it signifies more equality. In all of these models, the Beta coefficient is positive, meaning that as the value of this variable increases, the value of the dependent variable also increases. The dependent variable in this case is the difference between the Clinton and Sanders vote, as a subtraction (Clinton-Sanders), so is positive when Clinton wins, and negative when Sanders wins. What that implies is that in the states where you have greater levels of inequality, they are voting in larger numbers for Clinton. One might propose that poverty or education might be at work, rather than inequality, as such. However, several measures for poverty and education were included in the algorithm, and even accounting for those, income inequality is by far the more powerful predictor.
In a prior effort to find patterns in the data, I attempted to control for "cultural" factors, specifically, "Southern Culture," since there seemed to be early differences between Sanders vs Clinton wins based on the latter's southern victories. This Southern Culture Index did not make any of the previous best models. However, it was useful in one of the current models, Dem 1. As was previously shown, this index consists of four variables: % of White Evangelicals, death rates, teen birth rates, and slave population in 1860. A higher value means that state has stronger characteristics of "southern culture." Since the Southern Culture Index is positive in the Dem 1 model, it describes that the "more southern culture" a state has, the more likely it is to vote for Clinton. This result is fairly obvious just looking at a map of the Democratic contest so far. However, in the Dem1 model, what the results show is that it is the strongest of the four predictors.
In Dem2, the slave population variable is present by itself, and unsurprisingly given the results of the Southern Culture Index, as the slave population of 1860 increases, those states vote more strongly for Clinton. Similarly, in Dem 3, White Evangelicals appears as its own predictor, and like these other two, as they increase, so does support for Clinton. Conversely, hose that claim no religious affiliation appears in Dem4, and as expected, it is negative, showing that as this population is larger, that state votes more strongly for Sanders.
There are three jobs variables that made it into the final models: 1) "Change in production and transportation jobs from 2005-2014," 2) "Change in men's jobs in arts, entertainment, recreation, accommodation, & food service from 2000-2013,", and 3) men working retail in sporting goods, hobby, or toy stores in 2013." The most conservative way to interpret these results, when put into the context of the large number of jobs variables that were used to test models, is that the patterns in these jobs were just coincidentally, mathematically similar to the pattern of voting in the first 32 states which have voted so far this year. That may be the most one can say. Even if one were to assume that these results aren't simply a coincidence, one would still have to come up with a rationale for why, for example, when it comes to arts & food service jobs, the important factor was the change from 2000-2013, as opposed to 2005-2014. Similarly, one would have to explain why the production & transportation jobs change was important from 2005-2014, but not from 2000-2013. And why, of all of the possible job types, why these--why arts & food service, or why transportation & production? Perhaps there is a good explanation for these patterns, but I do not have one. My best guess is that it is coincidence, until other evidence is produced--for example, a good theory is presented, or the models correctly predict the rest of the state-level votes.
The jobs variables are mostly negative, meaning that as this value goes down, the dependent variable goes up, and vice versa. As jobs are lost over time, these variables become more negative, or as jobs increase over time, these variables become more positive. Since these values are mostly negative, presuming the results aren't simply a coincidence, it shows that in these states, as jobs in these specific fields are lost, they vote more strongly for Clinton. As jobs in these specific fields are gained, they vote more strongly for Sanders. One exception, is between Dem2 and Dem4. In Dem2, this is the broadest jobs variable in this sector--it includes arts, entertainment, recreation, accommodation, and food, and as these jobs are lost, that state votes more strongly for Clinton. However, in Dem4, this is just food and accommodation jobs. This variable is positive, meaning that as these jobs are lost, these states tend to vote more strongly for Sanders.
As before, I gave preference to those models that had the smallest residuals, the largest adjusted R-square, the lowest model p-values and variable p-values, the lowest BIC, and correctly fit the most states. All four models presented here have an adjusted R-square above 82%, and correctly predict either 31 or all 32 of the states that have voted as of April 2. All have model p-values less than 0.0001, and all variables have variance inflation factors less than 2.5. All individual variables have p<0.05, except for Dem 3, where one variable has p<0.07.